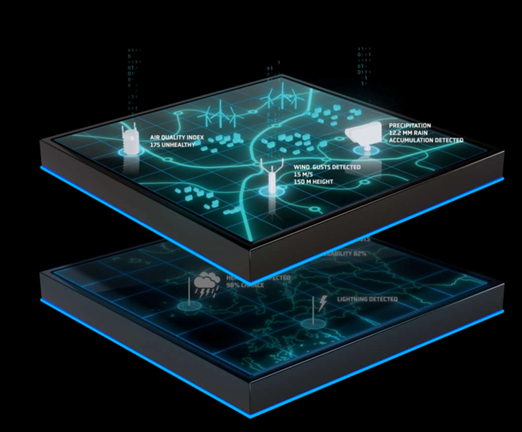
Use Cases
Products
Developer
/
Categories
All Categories
All
News
4.17.2024
4.5.2024
Educational
3.8.2024
3.7.2024
2.28.2024
Client Stories
2.12.2024
2.5.2024
Product
2.2.2024
2.1.2024
1.23.2024
01
09